
I was burned many times after a faulty box has rebooted and all stored logs where lost. For troubleshooting it is very important to have all relevant log data directly accessable. To have logs only stored on the productive devices ends in a troubleshooting nightmare. I have seen networks without a Syslog or NTP server, where it was a very time consuming job to find the cause for an outage in the log data. To have a powerfull log infrastructure is a must have in my opionion if you don´t wont to end in the debugging hell.
Basic Logging Setup
As a general guidline for logging I recommand that all devices no matter waht it is send their logs to an external logserver. Mostly that is a syslog server but here it depnends on the divce type and vendor. The next step is that all devices should use a NTP server so that all loggs come into your logserver with the consistant time stamps. Try to collect as much as possible from your devices. You can apply later filters to reduce the amount of massages, but a massage that you never have received can be the missing hint in a truobleshooting hunt.
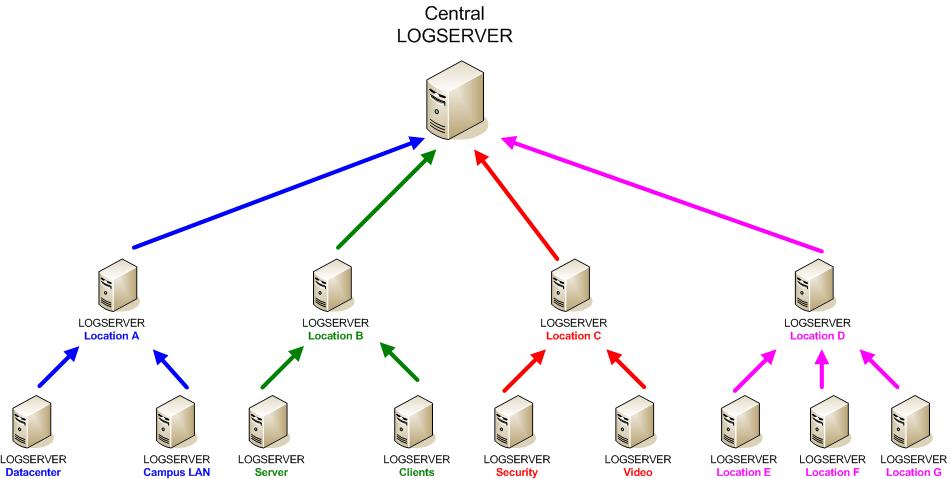
Logging Topology
Logging should be organized like a tree. Decentralized Logservers collect local massages and do a spoofed proxy forwarding to the next Logging server in the hirachy. Here it depends on your organization how you manage your logservers. Very common are the models of separtion by location or IT department. It also gives you a better handling if e.g. the Storage department has its own log server and use that for daily troubleshooting, when it comes to a problem that involves besides the storage devices also the network gear you can go to the central log server and see the massages from the storage and the network log server in one view. You can correlate the massages toghter and see how one event triggered an other event. That helps a lot in finding complex issues in modern infrastrutures, where you have a high grade of integrations between the different components.
One format to rule them all
It is a challenge to get all the different masseges to one format that you can analyse. It starts with the different Log formats, syslog is the most common, but there are some vendors that do their own protocolls like Checkpoint. Here you need a log server that can collect these different input protocolls and formats and parse them into a standard. It is very frustrating when you have to browse between 5 different tools and formats to view logs for an incedent that you are investigating. Besides the classic log data you have on most network gear also flow data from IPFIX; Netflow, JFlow, SFlow … available. It can be very usefull to have the ability to corelate the logs and the flow data together especially for IT forensics.
The right View for your Logs
In the past we had only the command line to view the log data. But when you you do advanced analysis of log data a graphical interface becomes really handy. Open source projects like greylog2 have a powerfull web interfaces that brings clever extra features on the table. It is possible to build a complete Logging infrsatructures with open source. At the end of the logging hirachy it makes sense to have an SIEM solution in place wich has more capabilitys than a normal syslog server. Besides the security aspect a SIEM system can also be used for troubleshooting network problems. There are not many open Source SIEM systems available, I am only aware of Alien Vault OSSIM, wich is limited to one user and the free version of Splunk wich is limited to 500MB/Logdata per day. For testing in the lab both are a good option and on both solutions are full feature commercial versions available. Another usefull addon for logs is a visulization engine. Sometimes one graph can show you more than 1000 log entrys. Very interesting here is the commercial solution from ArcSight.
For further Informations about Logging I can also recommand the packet pushers show 192 Logging Desgn & best Practice. In the show the packet pushers hosts had a discussen about Logging with Jay Swan, Wes Kennedy and greylog develoopper Lennart Koopman.
http://packetpushers.net/show-192-logging-design-best-practices/




Good post.
I’ve been playing with VMware LogInsight in the lab quite a bit, and I’m a big fan of its machine learning on formatting/format, as well as having an agent that can be configured to tail log files and turn them into log feeds (nice for VMware View, and other apps that put logs in 20 different files/locations).
Traditional SNMP/Ping/Flow monitoring just hasn’t been cutting it, and i’m finding that 90% of transient failure issues that don’t get caught with traditional pull monitoring is generally in a log feed somewhere.
The key is take the tribal knowledge in your org of various key log strings, and put them into dashboards, and generate tickets etc, so that transient APD issue, or SIOC error can be acted upon without having to bring in the senior resources.
Havn´t tested VMWare LogInsight so far. Sounds very interesting hopefully I find some time to try it out.
Cheers
Dominik
Great post!
I’m still a big fan of syslog-ng, although I honestly haven’t spent much time with greylog2. I’ll be needing to upgrade our centralized syslog server to CentOS 6.x so I may take that opportunity to try something new.
Cheers!
Mike