
 IOS XE 16.x Denali
IOS XE 16.x Denali
It is quiet hard to track software release streams and available features sets across the different Cisco switch and router familys. I have been more than one time get confused with the same software release version on different platforms that has different feature sets. It is not nice when there is a feature missing that you had expected. Cisco has addressed that problem finally with the 16.x Denali release. Cisco has worked on the Denali release for 3 years to bring a unified SW release across multiple platforms. In the backround Cisco has 3 abstraction components the CLI, the unified SW Stack and the ASIC related part of the code. The big benefit here is that you didn´t need a separate
development team for each switch / device family. CLI and unified Software Stack can be developed centralized with one team across different products. That enables faster development for new features and feature parity across different device families. Besides the benefit of exactly the same CLI on all devices that runs Denali Cisco has also added a new WebUI that is completely rebuild and has more features and a better usebility than the previous web interface. Costumers have demanded this for a long time and finally Cisco has responded with Denali.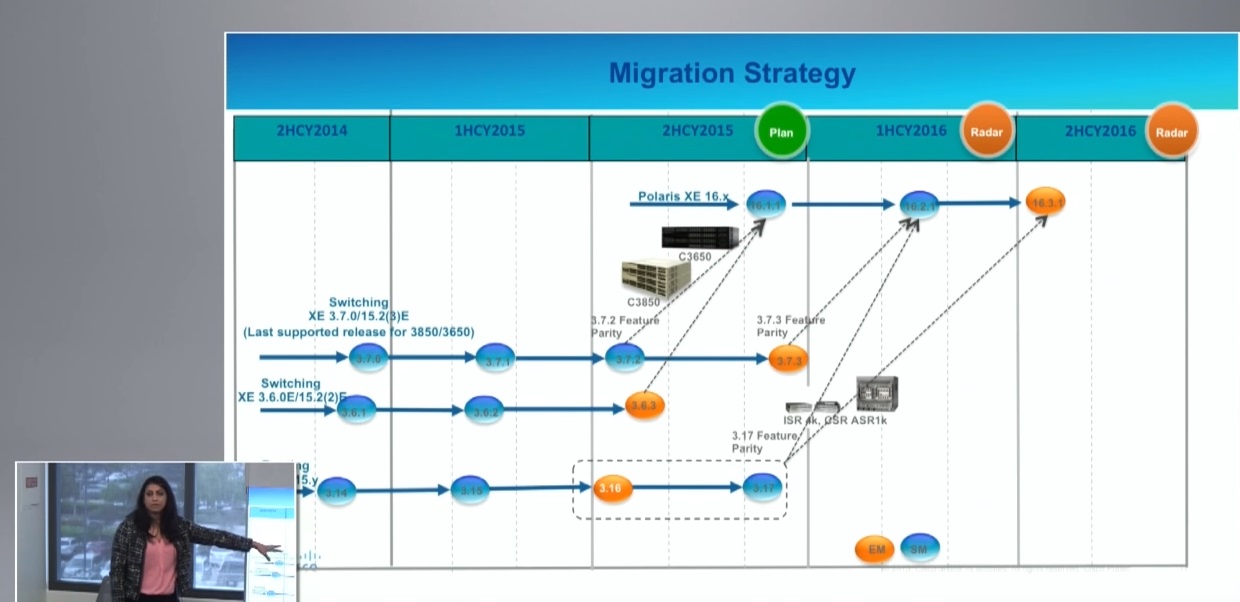
The Network Autobahn View
Thanks Cisco for releasing Denali. I have been waiting for this a long time. Besides Cisco internally all Cisco customers will benefit from this unified Software release approach. It makes tracking of software releases more easy and also the testing process. Cisco internally benefits also from a unified approach. I suggest that makes the development process faster and more efficient. At the end of the day hopefully the costumers get paid back with more new features that come out across multiple device platforms. I see here a general trend in the IT industry. It is needed to have an abstraction layer that is independent from the underlying hardware platform. Hopefully all new Cisco devices will follow this unified SW approach in the future.
Please accept YouTube cookies to play this video. By accepting you will be accessing content from YouTube, a service provided by an external third party.
If you accept this notice, your choice will be saved and the page will refresh.
 Silverpeak has shown their Unity EdgeConnect SDWAN solution. Silverpeak has done WAN optimization for many years and has leveraged from that for their SDWAN products.
Silverpeak has shown their Unity EdgeConnect SDWAN solution. Silverpeak has done WAN optimization for many years and has leveraged from that for their SDWAN products. The Business Unit inside of NETSCOUT that many of you know as Fluke networks has shown at the NFD11 their new TruView product. It is a monitoring and network measurement as a service offering.
The Business Unit inside of NETSCOUT that many of you know as Fluke networks has shown at the NFD11 their new TruView product. It is a monitoring and network measurement as a service offering. NetScout has put in serious thoughts to keep the complete process as simple as possible to get results fast and easy. After an endpoint is registered you get immediately results of the performance tests. The cloud based Pure View server presents the results of the performance test.
NetScout has put in serious thoughts to keep the complete process as simple as possible to get results fast and easy. After an endpoint is registered you get immediately results of the performance tests. The cloud based Pure View server presents the results of the performance test. Skyport Sytems has used the NFD11 to show the first time their new innovativ product.
Skyport Sytems has used the NFD11 to show the first time their new innovativ product. When the year is ending and everybody is thinking about XMAS in a lot of IT departments it starts to get hectic. There is some IT budget left and it has to be spended before the year is ending. I have seen this in many businesses and it is especially true for government organisations. So like at home where I have to assemble some Lego Toys for my children on XMAS there are delivered a lot of large packages at the office that have to be unboxed and rolled out into production before the year is ending. So not for all IT folks the end of the year is as relaxed as it should be. On the first weeks of the new Year I had often to do a lot of clean up work to get everything right for that was no time during the installation like monitoring and documentation.
When the year is ending and everybody is thinking about XMAS in a lot of IT departments it starts to get hectic. There is some IT budget left and it has to be spended before the year is ending. I have seen this in many businesses and it is especially true for government organisations. So like at home where I have to assemble some Lego Toys for my children on XMAS there are delivered a lot of large packages at the office that have to be unboxed and rolled out into production before the year is ending. So not for all IT folks the end of the year is as relaxed as it should be. On the first weeks of the new Year I had often to do a lot of clean up work to get everything right for that was no time during the installation like monitoring and documentation.




